Find All Url That Is Not An Html Attribute Or Content Of A Hyperlink Tag
Solution 1:
Expecting Valid HTML Output
Here is rough guide to get you started.
- Use a HTML5 parsing engine like jsoup Java HTML Parser
- HTML5 specification deals with invalid HTML in a known specified way for predicable results.
- this parsing engine actually provides HTML modification methods too.
Parse your HTML something like this:
String html ="This is a url http://www.google.com <a href=\"http://www.google.com\" title=\"Go to Google\">Google</a>"; Document doc =Jsoup.parseBodyFragment(html); Element body = doc.body();- Find all your text nodes (non-HTML element bits)
- You can find an example of an jsoup text iterator in this answer.
- Test to see if the text looks like a link (use your regex)
- Replace the text as indicated in the same example.
- Obtain the HTML of the complete modified document.
- Sit back and enjoy.
Edit 1 - The Crazy World of replacing in Invalid HTML
It seems the author of this question has indicated that the content is not valid HTML and requires the invalid HTML to be maintained - as such a HTML parser shouldn't be used as any HTML parser would likely output valid HTML when saving.
As indicated in my comment to the original question you can use negative look behinds in regex. But only a fool would parse HTML with RegEx - apparently we aren't so here is one possible example.
I wouldn't use this in production code - but it answers OP's question
The RegEx
Unfortunately Java doesn't support unlimited look-behinds so I have included the following limits:
- Tag name - max of 255 characters
- Spaces - max of 30 characters
- Attribute contents (including attributes and values) - max of 4098 characters
Negative Look-behind
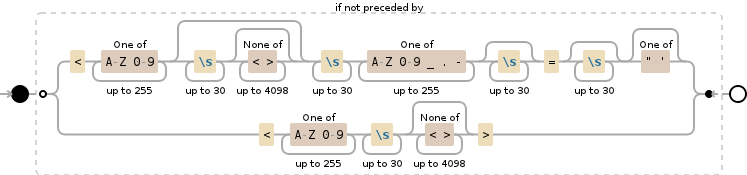 Note that this visualization is incorrect as
Note that this visualization is incorrect as [\p{L}0-9_.-] was replaced with [A-Z0-9_.-] to get visualisation to work - but \p{L} is technically more correct as "Any Unicode Letter" is possible.
Complete Regex
# Negative look-behind
(?<!
## N1: Looks like an HTML attribute value inside a HTML tag
### N1: Tag name
<[A-Z0-9]{1,255}
### N1: Any HTML attributes and values
(?:\s{1,30}[^<>]{0,4098})?
### N1: The begining of a HTML attribute with value
\s{1,30}
[\p{L}0-9_.-]{1,255}
\s{0,30}=\s{0,30}
### N1: Optional HTML attribute quotes
["']?
|
## N2: Looks like the start of an HTML tag text content
### N2: Tag name
<[A-Z0-9]{1,255}\s{1,30}
### N2: All HTML attributes and values
[^<>]{0,4098}
### N2: End of HTML opening tag
>
)
## Positive match: The URL value
((?:https?|ftp|file)://[-a-zA-Z0-9+&@\#/%?=~_|!:,.;]*[-a-zA-Z0-9+&@\#/%=~_|])
The Java
import java.util.*;
import java.lang.*;
import java.io.*;
import java.util.regex.*;
classCrazyInvalidHtmlUrlTextFindAndReplacer
{
publicstaticfinalStringEXAMPLE_TEST="This is a url http://www.google.com <a href=\"http://www.google.com\" title=\"Go to Google\">Google</a><a href=\"http://www.google.com\">http://www.google.com</a><img src=\"http://www.google.com/image.jpg\"><div data-url=\"http://www.google.com\"></div>";
publicstaticfinalStringEXPECTED_OUTPUT_TEST="This is a url <a href=\"http://www.google.com\">http://www.google.com</a> <a href=\"http://www.google.com\" title=\"Go to Google\">Google</a><a href=\"http://www.google.com\">http://www.google.com</a><img src=\"http://www.google.com/image.jpg\"><div data-url=\"http://www.google.com\"></div>";
publicstaticvoidmain(String[] args)throws java.lang.Exception
{
System.out.println("Starting our non-HTML search and replace...");
StringBufferresultString=newStringBuffer();
StringsubjectString=newString(EXAMPLE_TEST);
System.out.println(subjectString);
try {
Patternregex= Pattern.compile(
"# Negative lookbehind\n" +
"(?<!\n" +
"## N1: Looks like an HTML attribute value inside a HTML tag\n" +
"### N1: Tag name\n" +
"<[A-Z0-9]{1,255}\n" +
"### N1: Any HTML attributes and values\n" +
"(?:\\s{1,30}[^<>]{0,4098})?\n" +
"### N1: The begining of a HTML attribute with value\n" +
"\\s{1,30}\n" +
"[\\p{L}0-9_.-]{1,255}\n" +
"\\s{0,30}=\\s{0,30}\n" +
"### N1: Optional HTML attribute quotes\n" +
"[\"']?\n" +
"|\n" +
"## N2: Looks like the start of an HTML tag text content\n" +
"### N2: Tag name\n" +
"<[A-Z0-9]{1,255}\\s{1,30}\n" +
"### N2: All HTML attributes and values\n" +
"[^<>]{0,4098}\n" +
"### N2: End of HTML opening tag\n" +
">\n" +
")\n" +
"## Positive match: The URL value\n" +
"((?:https?|ftp|file)://[-a-zA-Z0-9+&@\\#/%?=~_|!:,.;]*[-a-zA-Z0-9+&@\\#/%=~_|])",
Pattern.CASE_INSENSITIVE | Pattern.UNICODE_CASE | Pattern.COMMENTS);
MatcherregexMatcher= regex.matcher(subjectString);
while (regexMatcher.find()) {
System.out.println("text");
try {
// You can vary the replacement text for each match on-the-fly// !!!!!!!!!// @todo Escape the attribute values and content text.// !!!!!!!!!
regexMatcher.appendReplacement(resultString, "<a href=\"$1\">$1</a>");
} catch (IllegalStateException ex) {
// appendReplacement() called without a prior successful call to find()
System.out.println("IllegalStateException");
} catch (IllegalArgumentException ex) {
// Syntax error in the replacement text (unescaped $ signs?)
System.out.println("IllegalArgumentException");
} catch (IndexOutOfBoundsException ex) {
// Non-existent backreference used the replacement text
System.out.println("IndexOutOfBoundsException");
}
}
regexMatcher.appendTail(resultString);
} catch (PatternSyntaxException ex) {
// Syntax error in the regular expression
System.out.println("PatternSyntaxException");
System.out.println(ex.toString());
}
System.out.println("result:");
System.out.println(resultString.toString());
if (resultString.toString().equals(EXPECTED_OUTPUT_TEST)) {
System.out.println("success!!!!");
} else {
System.out.println("failure - expected:");
System.out.println(EXPECTED_OUTPUT_TEST);
}
}
}
No idea what the performance would be like on this - look-behinds are expensive - that's on top of RegEx generally being expensive too.
Solution 2:
As discussed in the comments to the question, solving this using a regular expression only is hard (may be impossible?). Below is an XSLT Stylesheet, that does a preprocessing step to remove all attributes and all anchor tags from the input html.
<?xml version="1.0" encoding="ISO-8859-1"?><xsl:stylesheetversion="1.0"xmlns:xsl="http://www.w3.org/1999/XSL/Transform"><xsl:templatematch="node()"><xsl:copy><xsl:apply-templatesselect="node()"/></xsl:copy></xsl:template><xsl:templatematch="a"></xsl:template></xsl:stylesheet>Then you can run your regex to extract the remaining urls, which will be much simpler.
If your input html is not valid, then use jtidy, htmlcleaner or htmltidy as a further preprocessing step.
Hope this helps.
Solution 3:
Based on suggestion by Dean and the mentioned example, here's the "solution" to the problem. Keep in mind that it's a very expensive one due mainly to the parsing of HTML string (~160ms on quad-core/16GB RAM MBPr). This solution also handles both valid and invalid HTML. Keep in mind there is a little hack around the limitation of JSOUP to make sure extra tags are not included to make the end result a valid HTML. I really hope someone can come up with a better solution, but here it is for now.
publicstatic String makeHTML(String htmlText){
booleanisValidDoc=false;
if((htmlText.contains("<html") || htmlText.contains("<HTML")) &&
(htmlText.contains("<head") || htmlText.contains("<HEAD")) &&
(htmlText.contains("<body") || htmlText.contains("<BODY"))){
isValidDoc = true;
}
Documentdoc= Jsoup.parseBodyFragment(htmlText);
finalStringurlRegex="\\b(https?|ftp|file)://[-a-zA-Z0-9+&@#/%?=~_|!:,.;]*[-a-zA-Z0-9+&@#/%=~_|]";
final List<TextNode> nodesToChange = newArrayList<>();
final List<String> changedContent = newArrayList<>();
NodeTraversornd=newNodeTraversor(newNodeVisitor() {
@Overridepublicvoidtail(Node node, int depth) {
if (node instanceof TextNode) {
TextNodetextNode= (TextNode) node;
Nodeparent= node.parent();
if(parent.nodeName().equals("a")){
return;
}
Stringtext= textNode.getWholeText();
List<String> allMatches = newArrayList<String>();
Matcherm= Pattern.compile(urlRegex)
.matcher(text);
while (m.find()) {
allMatches.add(m.group());
}
if(allMatches.size() > 0){
Stringresult= text;
for(String match : allMatches){
result = result.replace(match, "<a href=\"" + match + "\">" + match + "</a>");
}
changedContent.add(result);
nodesToChange.add(textNode);
}
}
}
@Overridepublicvoidhead(Node node, int depth) {
}
});
nd.traverse(doc.body());
intcount=0;
for (TextNode textNode : nodesToChange) {
Stringresult= changedContent.get(count++);
NodenewNode=newDataNode(result, textNode.baseUri());
textNode.replaceWith(newNode);
}
Stringprocessed= doc.toString();
if(!isValidDoc){
intstart= processed.indexOf("<body>") + 6;
intend= processed.lastIndexOf("</body>");
processed = processed.substring(start, end);
}
return processed;
}
{kind=link}
Post a Comment for "Find All Url That Is Not An Html Attribute Or Content Of A Hyperlink Tag"